

Ubiquity Backs ElastixAI: Fixing AI’s Most Expensive Mistake
AI isn’t limited by models anymore—it’s limited by inefficient hardware. ElastixAI flips the equation

Ubiquity recently backed ElastixAI, a company tackling one of the most important—and most overlooked—problems in AI:
Not how we build models, but how we run them.
AI is not bottlenecked by models anymore. It’s bottlenecked by inference—the cost, efficiency, and infrastructure required to actually deploy these systems at scale.
And right now, that layer is breaking.
Every week, new ML techniques unlock meaningful gains—quantization, sparsity, better attention mechanisms, longer context. But those gains rarely show up in production. Not because the ideas are wrong, but because the hardware can’t keep up.
Hyperscalers made a reasonable bet: deploy GPUs at massive scale and refresh every few years. That worked when models evolved slowly. It breaks when model optimization evolve weekly.
Your hardware is already out of date.
We’re trying to run modern AI on hardware that acts more like a fixed-function calculator than a programmable system. And then we try to fix it by buying more GPUs. That’s not scaling. That’s scaling a broken system.
ElastixAI exists to fix this.
The Hidden Tax on Every Token
This mismatch shows up everywhere once you look for it.
New ML optimizations should deliver step-function improvements. In practice, they get watered down because existing hardware can’t support them natively. A technique like 4-bit quantization should unlock dramatic gains, but when you force it through hardware that wasn’t designed for it, most of the benefit disappears.
At the same time, the cost structure is moving in the wrong direction. Memory is becoming the dominant expense, with high-bandwidth memory costing an order of magnitude more than traditional DRAM. Compute is underutilized—large portions of modern GPUs sit idle during inference workloads. And power requirements are ballooning to levels that strain real-world data center constraints.
We are building increasingly powerful models on infrastructure that wastes most of its capability.
That’s not a marginal inefficiency. That’s a structural problem.
Why Elastix Exists
Elastix flips the stack.
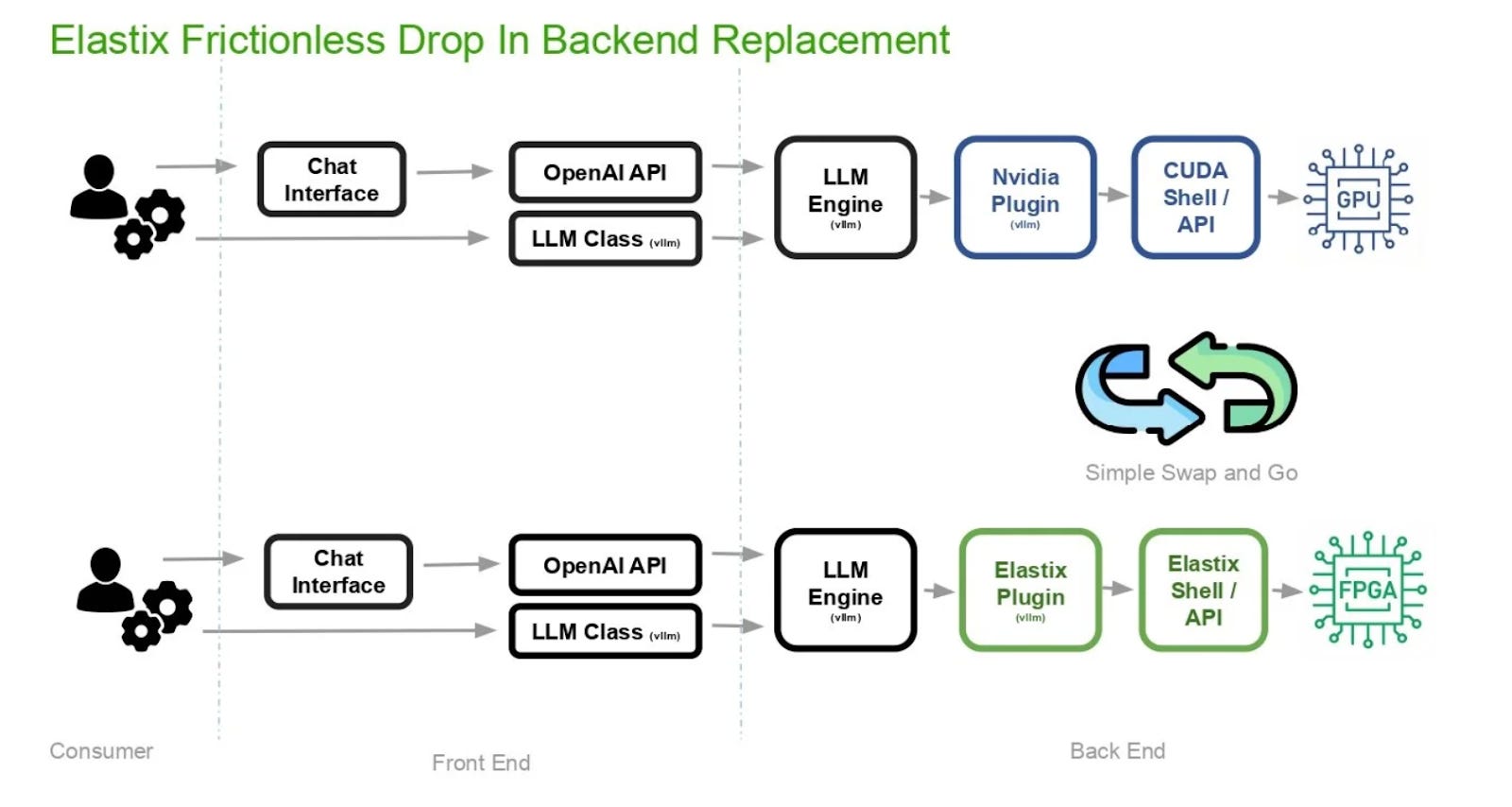
Instead of forcing models to conform to hardware, Elastix makes hardware conform to models. The key is reconfigurable compute—specifically, FPGAs.
Unlike GPUs, which are fixed after manufacturing, FPGAs can be reconfigured at the silicon level. Elastix takes advantage of this by effectively compiling ML models into hardware, allowing each model to run on a system tailored to its exact needs.
That means new ML techniques can be implemented directly in hardware, without software workarounds. It means better utilization, lower memory overhead, and dramatically improved efficiency. And it means you’re no longer waiting years for the next chip cycle to benefit from advances in ML.
Early results are striking: significant cost reductions versus GPU-based systems and the potential for 10x-50x cost efficiency gains, over various user latencies, as models continue to evolve.

What Would You Do With 100x More Tokens?
The right way to think about Elastix is not “is this cheaper?”
It’s: what becomes possible if inference is dramatically more efficient?
If the cost of generating tokens drops by an order of magnitude or more, entirely new categories of applications open up. Fast reasoning becomes viable in places it isn’t today. Power-constrained environments can run meaningful models locally. Context windows can expand without blowing up cost. AI starts to look less like a premium feature and more like infrastructure.
This is the kind of shift that doesn’t just improve existing use cases—it creates new ones.
Why Now
This approach only works now because several trends have converged.
First, ML innovation is outpacing hardware cycles by a wide margin. Second, inference has become the dominant cost center for many AI applications. And third, the ecosystem has matured to the point where a handful of ML models are generating multiple billion dollars in revenue.
ElastixAI is not just a hardware play—it’s a tightly integrated stack spanning ML optimization, software development, and hardware reconfiguration. This is a real-time HW-SW-ML co-design. It means the hardware can evolve with the same pace as software and machine learning optimizations all of this without the need of taping out a new silicon.
That combination is what allows them to capture the gains that today’s systems leave on the table.
Why ElastixAI Matters
Every major AI player today is making the same implicit bet: that the current GPU-centric stack will hold.
Elastix is making the opposite bet—that the future belongs to adaptive compute systems that evolve at the pace of software.
If that’s right, this is not a niche optimization. It’s a new layer of the AI stack.
Lower costs lead to more usage. More usage leads to new applications. And new applications expand the market. This is the kind of compounding effect that defines platform shifts.
The Team That Should Be Building This
This is not a generic hardware startup.
The founding team previously built Xnor.ai, pioneering deep learning quantization and efficient computer vision algorithms such as Xnor-Net and YOLO, which was acquired by Apple. They then spent years inside Apple and Meta working on large-scale ML systems, including contributions to Apple Intelligence and LLaMA-class models.
They’ve worked at the exact intersection this problem requires: ML algorithms, systems, and hardware. And they’ve done it both in startups and inside some of the most advanced AI organizations in the world.

Where They Are Today
Elastix is still early, but the core system is working and demonstrating meaningful efficiency gains. The company is based in Seattle and backed by Ubiquity and a strong set of investors.
The focus now is moving from proving the technology to scaling it in real-world deployments. They are already generating tokens using a variety of LLM models in hundreds of billion parameters and running them on multiple off-the-shelf FPGAs which are available to scale in the market.

The Bottom Line
AI is going to be constrained by economics, not intelligence.
Whoever fundamentally improves inference efficiency doesn’t just win on cost—they unlock entirely new capabilities.
Elastix is attacking that problem at its root. Not by building slightly better models or slightly better chips, but by rethinking how models and hardware interact in the first place.
If they’re right, every token gets cheaper, every model gets faster, and a whole new class of applications becomes viable.
That’s the kind of shift worth paying attention to.
Ubiquity Ventures — led by Sunil Nagaraj — is a seed-stage venture capital firm focused on startups building software that reaches into the real world. In a screen-obsessed world, we focus on "software beyond the screen" startups, which include technology companies that apply AI, software, and smart hardware to physical problems and systems that you can touch, hear, and feel.
If your startup fits this description, reach out to us.